



Semantic Turkey Developers Manual
This section provides detailed information for people interested in developing extensions for Semantic Turkey or even in modifying the core system. Currently, it contains generic information about the architecture of the system. We will add more details soon.
Introduction
We provide here more insights on the behind-the-stages of Semantic Turkey.
You may then get more information about the structure of the Semantic Turkey project, by learning about each of its composing modules and getting through their apidocs
Building Semantic Turkey
Detailed instructions for building Semantic Turkey are available here.
Semantic Turkey Architecture
The architecture of Semantic Turkey (figure below) offers an extensible application level, with services organized through Spring Dynamic Modules and published as OSGi services
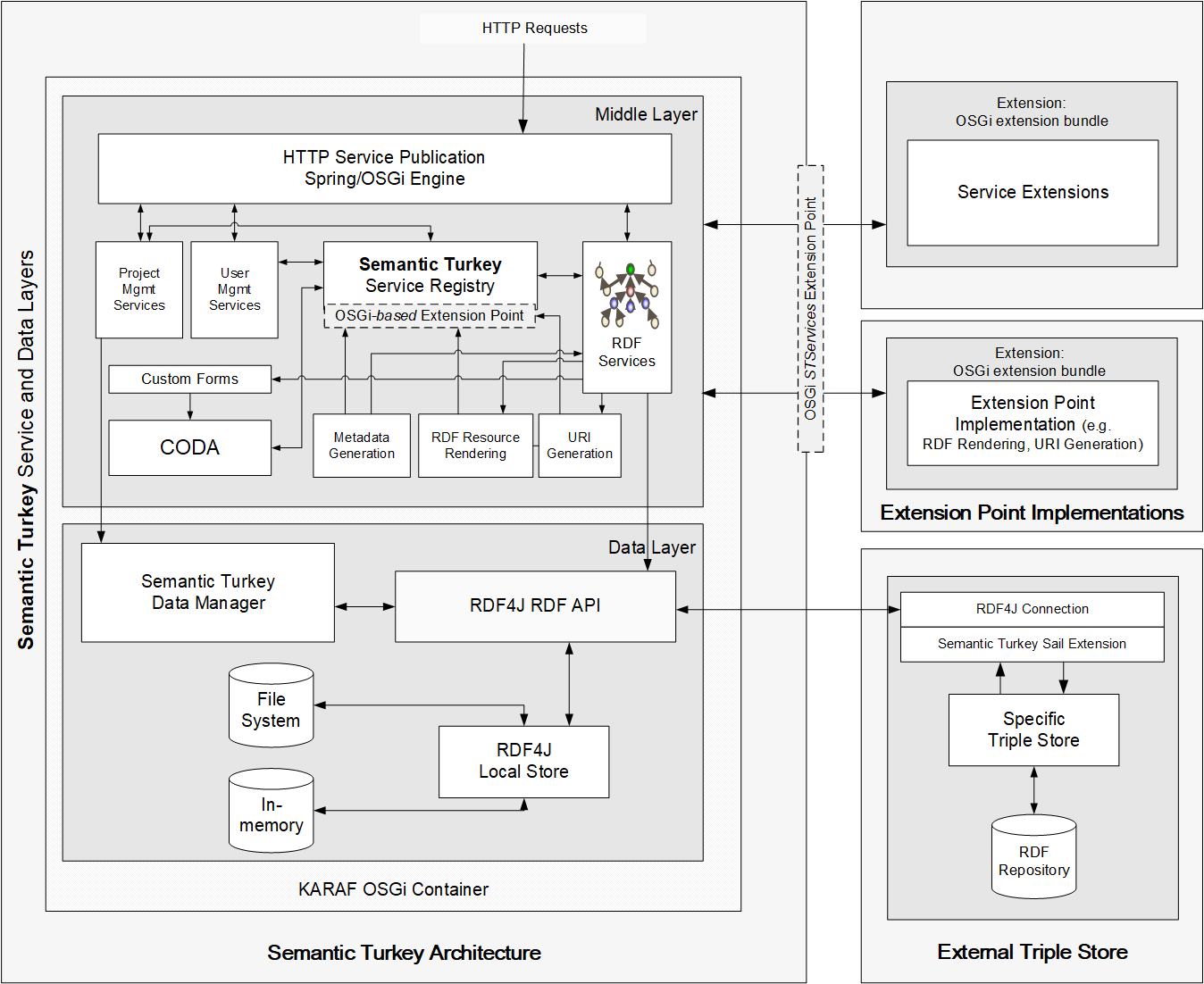
Service Layer
Services are implemented as Java methods, automatically converted - through a series of conventions - into REST-like web services. The application comes hosted on the Karaf OSGi container. The set of services can be incremented, thus augmenting the functionalities of the platform, through the development of dedicated extensions.
Data
Semantic Tukey relies on the RDF middleware RDF4J for managing connections to triple stores and for querying/manipulating data.
On top of RDF4J, Semantic Turkey provides.
- a connection component for connecting to various triples stores and through different modalities, handing repository configurations etc..
- a layered query builder for facilitating connection/transaction management, query composition, complementing queries, processing/enriching query results etc..
The rationale for these additional layers is to provide user-driven perspectives on the connection, limiting operations (e.g. read operations get access to a repository connection proxy forbidding all write operations), simplifying query development (e.g. the developer never has to resolve the lexicalization of resources, this is normally managed by ST through a dedicated extension points, with the connected plugin handing out to ST the query fragment to be inserted into the service query) and benefiting from other facilities provided by the above components.
Connecting to other triple stores
Since version 1.0, Semantic Turkey allows for creation of repositories by using the embedded RDF4J store or by connecting to an RDF4J compliant triple store through a remote connection. Tested triplestores for remote connections are: RDF4J itself, and GraphDB (GDB). The historical rationale for this choice is explained here (question on external triple stores).
The compatiblity with other triple stores should be analyzed on the basis of the following aspects:
- compliancy with RDF4J API, through a remote repository connection
- internal compliancy with the RDF4J Sail framework
- SPARQL compatibility
The first aspect is necessary in order to connect to the store. Some triplestores provide RDF4J compatible client libraries, exploiting other proprietary protocols but wrapping them with RDF4J API. These repositories could be possibly included in the range of storage solutions for ST.
The second aspect is twofold: mainly, it is important for the activation of features such as History and Validation. In order to enable them, we have developed a change-tracking component (implemented as a Sail) that must be deployed into the triplestore, providing that the triplestore is compliant with the Sail framework. Secondly, sail-compliant triple stores can be easily accessed by ST for configuring and creating repositories into them (the creation of a project in ST involves the handing of a Sail configuration), while others would foresee the creation of the repository directly through the store, and later connecting the repo from the project in ST.
The third aspect, while not binding technologically the store, is important as well: the SPARQL compatibility is not limited to implementing the range of SPARQL 1.1 features that are expected to be found by ST, but to the way queries are resolved. Despite the standardization efforts performed by the W3C for providing uniform languages and protocols for the web, triplestores are not always fully interchangeable even by considering the sole SPARQL compliancy. The reason is performance and query resolution policies. Often, different stores respond differently to queries because of different resolution strategies adopted by their query processors. Striving at interoperability, we have tried to organize queries in such ways that their resolution would follow our expected order (e.g. byusing nested queries), yet it cannot be guaranteed that all stores would perform the same on the same set of queries developed for ST services. If a store has a very different resolution strategy and this result in many services performing badly, then there is not much that can be done (with reasonable effort).
So, reassuming:
- if a triplestore natively supports (no need of dedicated libraries) connections from an RDF4J client, it can be remotely connected without need of developing any specific solutions (no coding necessary, just create repositories in the store and create projects in ST, remotely connecting to the created repos).
- if the triplestore is also compliant with the Sail stack framework, then it is possible to deploy into it the change-tracking component and exploit the History and Validation features of ST. Optionally, a Sail configuration for it can be developed and dynamically deployed into ST (this requires coding the configuration, but requires no change in ST, as it foresees an extension point for configurations which can be dynamically hot-plugged through OSGi).
- if the triplestore supports connections from a proprietary library implementing the RDF4J API, then some coding is necessary in order to embed the library into ST (currently there is no general extension point for that, so ST needs to be modified)
In all cases above, the SPARQL compatibility must be verified for the candidate triplestore. We suggest first to confirm compliancy with SPARQL 1.1 by the store specifications, and then it should be in any case tested for its performance response to ST queries.
For the above reasons, we have recommended using RDF4J or GraphDB as external triplestores. GraphDB natively accepts RDF4J remote connections with no need of any dedicated library, and implements and supports the Sail stack mechanism, so that the change-tracking component can be used with it as well. The only thing that we developed specifically for GraphDB is a Sail configurator so that it is even possible to create GDB repositories remotely by completely specify their configuration.
If you have other triplestores that you would like to see connected to Semantic Turkey, you can investigate on their architecture and we can support you in developing (if necessary) the required components for connecting to it. These components might include:
- embedding the proprietary RDF4J of the store (if any) client into ST
- developing a Sail configuration for the specific store
Project Management
A dedicated Project Management section of the development manual details the structure of projects and how these are handled by the ProjectManager of Semantic Turkey.
Logging
Logging is managed through the Simple Logging Facade For Java (SLF4J) framework, in a log4j implementation provided by Pax Logging.
The log4j logging configuration file is located in:
<serverfolder>/etc/org.ops4j.pax.logging.cfg
See log4j manual if you don't know how to configure this logger
A System Restart is needed for changes on the logging preferences to take effect
The logs will be stored in:
<serverfolder>/data/log/karaf.log
In order to log the SPARQL queries submitted by Semantic Turkey, the core logger of semantic turkey needs to be set to debug
log4j2.logger.semanticturkey.level = DEBUG
Extension Point development
Extension points are available for implementing in different ways existing functionalities of the system, thus enabling developers to virtually customize them according to any user need. Currently, available extension points include:
- Collaboration Backend. Support for different collaboration platforms. Currently, it is only available an instance for JIRA.
- Dataset Metadata Exporter. Support for the representation and export of metadata about the edited dataset according to different vocabularies (e.g. VoID, DCAT, LIME).
- Input/Output related extension points
- Deployer. Support for exporting data to different types of destination. More specifically, a RepositorySourcedDeployer interacts with a triple-oriented destination (typically, a triple store compliant to the SPARQL 1.1 Graph Store HTTP Protocol), while a StreamSourcedDeployer is able to export data (previously serialized/reformatted by a Reformatting Exporter) to a stream-based information host (e.g. an SFTP server, or a genetic HTTP endpoint)
- Reformatting Exporter. Support for the conversion of RDF data to a byte sequence, usually conforming to non-RDF formats
- Loader. Support for loading data from a different types of sources. More specifically, a RepositoryTargetingLoader is able to import triples from a triple-oriented source (typically, a triple store compliant to the SPARQL 1.1 Graph Store HTTP Protocol), while a StreamTargetingLoader is able to load data to any stream-based information host (e.g. an SFTP server, or a genetic HTTP endpoint), before handing it to an RDF Lifter for the conversion into RDF triples
- RDF Lifter. Support for diverse input formats, being in charge of transforming their data to RDF
- RDF Transformer. Support for transforming RDF data (both in input and output procedures), by filtering out triples and creating new data.
- Rendering Engine. Production of intelligible labels for representing an RDF resource in a user interface. Each Rendering Engine provides a SPARQL fragment that is usually connected to the queries of the various resource retrieving services.
- RepositoryImpl Configurer. Support for different kinds of triple stores. Currently, there are implementations for various storage solutions of Eclipse RDF4J and for Ontotext GraphDB Free/SE.
- Search Strategy. Support for choosing different implementations of different search operations.
- URI Generator. Automatic generation of URIs
- Dataset Catalog Connector. Support for different dataset catalogs, which can be used to search and than access existing datasets
The Extension Point Development Guide explains how the extension point architecture works, and which extension points have been activated and are recognized by the system.
Developing your first extension
We have a quite outdated tutorial for writing extensions (it was even written when there were a default Semantic Turkey UI extension for Firefox, plus much has been changed in the ). The tutorial can however be still useful for the server side.
The general rule is however to take inspiration from the st-core-services module of Semantic Turkey for developing service extensions. This module, though part of the Semantic Turkey project, can be managed as an independent project and is in fact deployed as separate OSGi bundle, that is loaded by the main system in an identical way to a third-party extension.